Quick Facts
- Category: Education & Careers
- Published: 2026-05-03 20:45:36
- How to Diagnose Multi-Agent System Failures with Automated Attribution: A Step-by-Step Guide
- How to Submit Effective Bug Bounty Reports to GitHub
- Flutter Makes Swift Package Manager Default for iOS and macOS, Bidding Farewell to CocoaPods
- Post-Pandemic Math Gender Gap Widens Globally, New TIMSS Data Reveals
- NVD Enrichment Changes: What Container Security Teams Need to Know
Why Rollout Generation Is the Training Bottleneck
If you have ever run reinforcement learning (RL) post-training on a language model for math reasoning, code generation, or any verifiable task, you know the pain of watching a progress bar crawl while your GPU cluster burns through rollout generation. A team of researchers at NVIDIA has tackled this exact pain point by integrating speculative decoding directly into the RL training loop—without sacrificing output distribution integrity.
The problem is structural. In a synchronous RL training step, the process breaks down into five distinct stages: data loading, weight synchronization and backend preparation (prepare), rollout generation (gen), log-probability recomputation (logprob), and policy optimization (train). Using Qwen3-8B as the target model, the team measured how long each stage takes under two common workloads: RL-Think (continuing training a reasoning-capable model) and RL-Zero (starting from a base model and learning reasoning from scratch). In both cases, rollout generation consumes between 65–72% of total step time. Log-probability recomputation and training together account for only about 27–33%. This lopsided distribution makes rollout generation the only stage worth accelerating—and it sets the ceiling for any improvement.
What Speculative Decoding Actually Does
Speculative decoding is a well-known technique for speeding up text generation. The idea is simple: use a smaller, faster draft model to propose multiple tokens at once, then let the larger target model (the one you are actually training) verify those tokens using a rejection sampling procedure. The critical property for RL is that this rejection procedure is mathematically guaranteed to produce the same output distribution as if the target model had generated those tokens autoregressively. There is no distribution mismatch, no need for off-policy corrections, and no change to the training signal. The rollouts are identical in distribution to what the target model would have generated on its own—just produced much faster.
This is a big deal because when you are doing RL post-training, the reward depends on the policy's own samples. Traditional speed-up tricks like asynchronous execution, off-policy replay, or low-precision rollouts all trade some amount of training fidelity for throughput. Speculative decoding trades nothing. You get the exact same outputs, just faster.
The System Integration Challenge
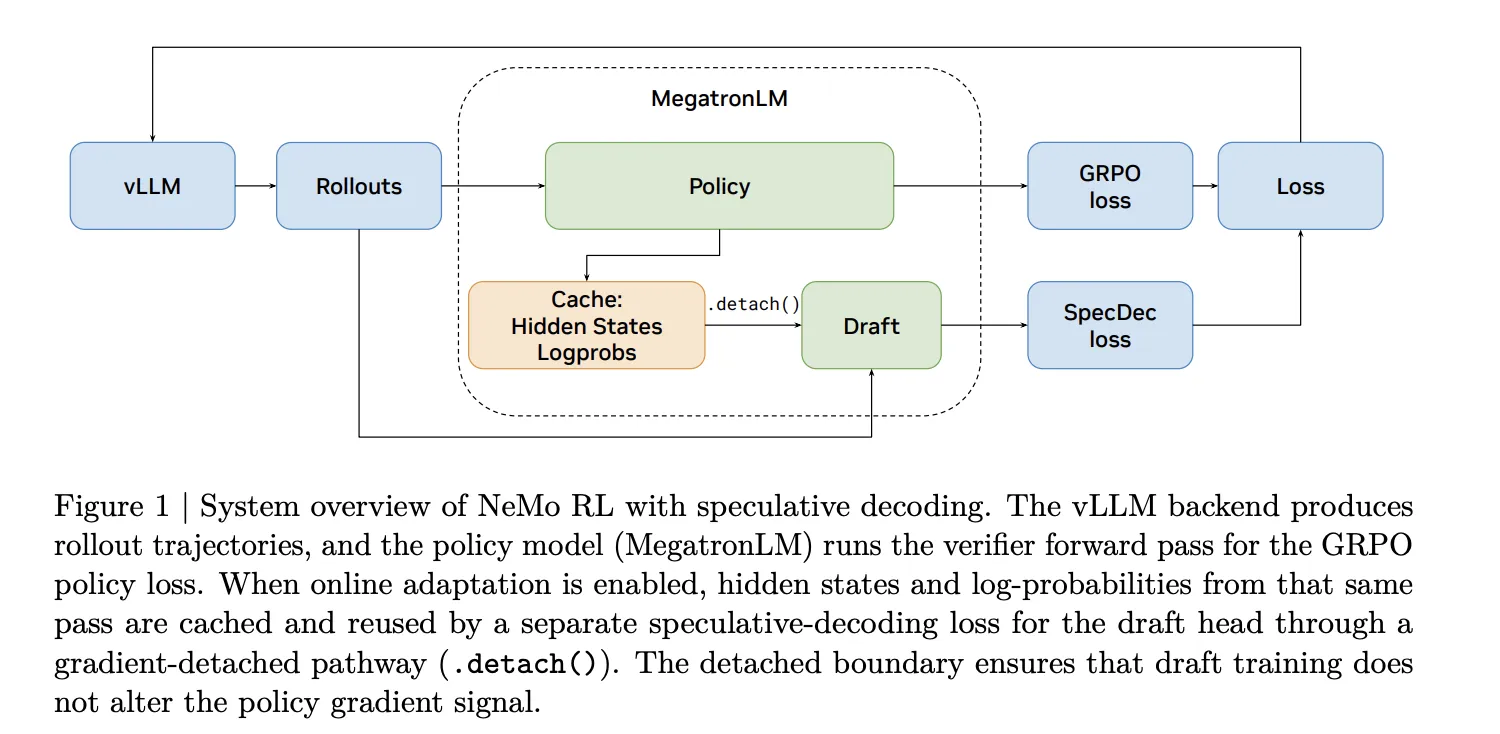
Adding a draft model to a serving backend is straightforward. Adding one to an RL training loop, however, is not. Every time the policy updates, the rollout engine must receive new weights. The draft model also needs to stay synchronized with the target model. The NVIDIA team solved this by integrating speculative decoding directly into NeMo RL v0.6.0 with a vLLM backend. The latest release officially ships speculative decoding as a supported feature, alongside the SGLang backend, the Muon optimizer, and YaRN long-context training.
To make the system work, they had to carefully manage weight transfers between the policy and the rollout engine, ensure that the draft model is updated frequently enough to stay useful, and handle the overhead of running two models simultaneously. The result is a seamless acceleration that does not disturb the existing training workflow.
Measured Speedups and Projections
The team reports that at the 8B parameter scale, speculative decoding achieves a 1.8× rollout generation speedup—the stage that was eating up two-thirds of the training time. This translates to a significant reduction in overall step time without any loss in training quality. For larger models, the benefits are even more dramatic. At 235B parameters, the projected end-to-end speedup is 2.5×, because the draft model remains relatively small while the target model grows.
These numbers are based on rigorous measurements using the RL-Think and RL-Zero setups on Qwen3-8B, and the 235B projection scales the known overheads and benefits using theoretical models. The research paper provides full details, and the integration is now available in the NeMo RL framework for anyone to use.
Implications for Large-Scale RL Training
The immediate takeaway is that speculative decoding offers a lossless, easy-to-integrate boost for one of the most expensive parts of RL post-training. For labs running massive clusters, a 1.8× speedup on the generation stage means shorter training cycles, lower power bills, or the ability to run more experiments in the same time. At 235B scale, a 2.5× end-to-end speedup could cut weeks of training down to days.
Moreover, because the technique preserves the exact output distribution, it does not change the training dynamics. Researchers can adopt it without worrying about introducing new hyperparameters or debugging distributional shifts. The fact that it is now built into NeMo RL v0.6.0 with vLLM and SGLang backends means that anyone already using the framework can enable it with minimal configuration.
Read the full paper for a deeper dive into the integration details and the theoretical guarantees behind the speedups.